
1. 개요
안녕하세요, 오늘은 파이썬에서 가장 널리 사용되는 머신러닝 라이브러리인 Scikit-learn에 대해 알아보려고 합니다. 데이터 분석에 필요한 다양한 머신러닝 알고리즘을 제공하는 이 라이브러리는 효율적이고 사용하기 쉬워 데이터 분석가들이 가장 많이 사용하는 라이브러리입니다. 그럼 이번 포스팅에서는 Scikit-learn 라이브러리의 개요, 데이터 분석에 자주 활용하는 주요 함수 및 예제, Scikit-learn 라이브러리 함수에 대해 알아보도록 하겠습니다.
2. Scikit-learn 개요
Scikit-learn은 다양한 분류, 회귀, 클러스터링 알고리즘과 데이터 전처리, 모델 선택, 평가 등의 기능을 제공하는 머신러닝 라이브러리입니다. 이 라이브러리는 효율적이고 사용하기 쉬운 API를 제공하며, 깔끔한 문서와 광범위한 커뮤니티 지원 덕분에 널리 사용되고 있습니다. 주요 정보는 아래 사이트를 확인 부탁드립니다.
scikit-learn: machine learning in Python — scikit-learn 1.3.0 documentation
Model selection Comparing, validating and choosing parameters and models. Applications: Improved accuracy via parameter tuning Algorithms: grid search, cross validation, metrics, and more...
scikit-learn.org
3. 데이터 분석에서 자주 활용되는 Scikit-learn 주요 함수 및 예제
1. 데이터 전처리
Scikit-learn은 데이터 전처리를 위한 다양한 함수를 제공합니다. StandardScaler는 특성의 평균을 0, 분산을 1로 변경하여 정규화를 수행합니다. 전처리 함수로는 MinMaxScaler(), OneHotEncoder(), LabelEncoder() 등이 있습니다.
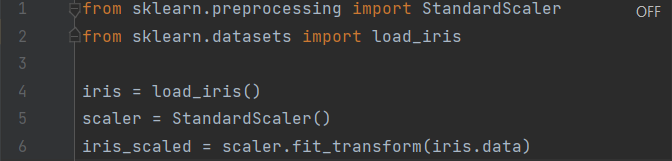
2. 분류 알고리즘
Scikit-learn은 다양한 가지 분류 알고리즘을 제공합니다. 예를 들어, LogisticRegression은 이진 분류 또는 다중 분류 문제에 사용됩니다. 분류 알고리즘 함수로는 DecisionTreeClassifier(), RandomForestClassifier() 등이 있습니다.

3. 모델 평가
Scikit-learn은 모델의 성능을 평가하기 위한 다양한 메트릭을 제공합니다. accuracy_score 함수는 분류 모델의 정확도를 계산합니다. 모델 평가 함수로는 mean_suqared_error(), r2_score() 등이 있습니다.

4. Scikit-learn 함수 리스트
1. 데이터 전처리 함수
1) StandardScaler() : 각 특성의 평균을 0, 분산을 1로 변경하여 모든 특성이 동일한 크기를 갖도록 데이터를 표준화합니다.
2) MinMaxScaler(): 모든 특성이 정확하게 0과 1 사이에 위치하도록 데이터를 조정합니다.
3) OneHotEncoder(): 범주형 변수를 원-핫 인코딩으로 변환합니다.
4) LabelEncoder(): 범주형 변수를 정수로 인코딩합니다.
2. 분류 알고리즘
1) LogisticRegression(): 로지스틱 회귀를 통해 이진 분류 또는 다중 클래스 분류를 수행합니다.
2) DecisionTreeClassifier(): 결정 트리 알고리즘을 이용하여 분류 문제를 해결합니다.
3) RandomForestClassifier(): 앙상블 알고리즘 중 하나인 랜덤 포레스트로 분류 문제를 해결합니다.
4) SVC(): 서포트 벡터 머신을 이용하여 분류 문제를 해결합니다.
3. 회귀 알고리즘
1) LinearRegression(): 선형 회귀를 통해 연속형 변수의 값을 예측합니다.
2) Ridge(): 리지 회귀를 통해 과적합을 방지하고 연속형 변수의 값을 예측합니다.
3) Lasso(): 라쏘 회귀를 통해 특성 선택이 가능하게 하고 과적합을 방지합니다.
4) ElasticNet(): 리지 회귀와 라쏘 회귀의 결합으로 과적합을 방지하고 연속형 변수의 값을 예측합니다.
4. 클러스터링 알고리즘
1) KMeans(): K-평균 클러스터링 알고리즘을 이용하여 비지도 학습으로 데이터를 그룹화합니다.
2) DBSCAN(): 밀도 기반 클러스터링 알고리즘을 이용하여 데이터를 그룹화합니다.
3) AgglomerativeClustering(): 계층적 클러스터링 알고리즘을 이용하여 데이터를 그룹화합니다.
5. 모델 선택 함수
1) train_test_split(): 데이터를 학습 세트와 테스트 세트로 분리합니다.
2) GridSearchCV(): 주어진 매개변수 값들의 조합 중에서 최적의 매개변수를 찾습니다.
3) cross_val_score(): K-겹 교차 검증을 수행하여 모델의 성능을 평가합니다.
6. 모델 평가 함수
1) accuracy_score(): 분류 모델의 정확도를 계산합니다.
2) confusion_matrix(): 분류 모델의 혼동 행렬을 생성합니다.
3) mean_squared_error(): 회귀 모델의 평균 제곱 오차를 계산합니다.
4) r2_score(): 회귀 모델의 결정 계수를 계산합니다.
5. 마치며
Scikit-learn은 파이썬을 활용한 데이터 분석 및 머신러닝에 필수적인 도구입니다. 이 라이브러리는 다양한 머신러닝 알고리즘과 데이터 전처리, 모델 평가 기능을 제공하며, 이를 활용하면 데이터 분석 과정을 효율적으로 수행할 수 있습니다. Scikit-learnn 라이브러리 외 데이터 분석에 사용되는 파이썬 필수 라이브러리에 대해 정리한 아래 포스팅도 참고 부탁드립니다.
[빅데이터 분석] 빅데이터 분석을 위한 필수 파이썬(Python) 라이브러리
1. 개요 데이터 분석은 기업의 의사 결정에 있어 결정적인 역할을 하며, 복잡한 문제를 해결하고, 가치를 창출하는 데 도움이 됩니다. 이러한 데이터 분석을 위해 주로 사용되는 프로그래밍 언어
onceadayedu.tistory.com
방문해주셔서 감사드립니다.
이글이 도움이 되셨다면, 공감, 댓글, 구독 부탁드릴께요!
'빅데이터 분석 > Python' 카테고리의 다른 글
| [빅데이터 분석] 빅데이터 분석을 위한 필수 파이썬(Python) 라이브러리 (0) | 2023.07.12 |
|---|---|
| [빅데이터 분석] 파이썬(Python) Seaborn 라이브러리를 이용한 데이터 시각화 (4) | 2023.07.12 |
| [빅데이터분석] 파이썬(Python) Matplotlib 라이브러리를 활용한 데이터 시각화 (0) | 2023.07.12 |
| [빅데이터 분석] 파이썬(Python) Pandas 라이브러리 활용한 데이터 분석 (0) | 2023.07.11 |
| [빅데이터 분석] 파이썬(Python) Numpy 라이브러리를 활용한 데이터 분석 (2) | 2023.07.11 |




